
# redis 分页
- 第一种方案:从redis拿出所有数据后,再做内存分页(不推荐),热点数据小的时候可以这样做,性能相差不是很大,但是当数据量大的时候,分页期间就会占用大量内存,或撑爆
- 第二种方案:基于redis的数据结构做缓存分页,这里又分2种(1.有序的;2:可以通过范围查找)
- 基于redis的list数据结构,直接通过list的数据结构,用range方法可以进行分页,在数据量大的时候,性能也很可观,但是当存在接口高并发访问时,这个list可能会无限延长,且里面的数据会存在很多重复
- 用hash和Zset来一起实现;Zset中存储有序的id字段,通过分页后拿到id,然后再用id去hash中取;zset里的value能存储的数据有限,比如主键id和时间戳或者uid和分数这样,但是列表数据,还要展示用户的头像,昵称等信息,这些信息 要么去mysql做in查询,但是一般对象数据会在hash里缓存一份
- 基于redis的ZSet数据结构,通过Zset这个有序集合我们也可以做分页,同样也是用range方法
# 哨兵模式的脑裂问题
- 脑裂分成两种:
- master假死导致的,master假死后,又选出了一个master,然后假死的master复活导致脑裂
- 网络分区导致的,这种一般通过过半机制解决
- 解决方案:
- redis
- _第一种问题:同zookeeper
- 第二种问题:min-slaves-to-write:N,定义最少的从库数量
- 一般这两个配置是一起使用的,表示主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了
- zookeeper
- 第一种问题:假设某个leader假死,其余的followers选举出了一个新的leader。这时,旧的leader复活并且仍然认为自己是leader,这个时候它向其他followers发出写请求也是会被拒绝的。因为每当新leader产生时,会生成一个epoch标号(标识当前属于那个leader的统治时期),这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求
- 第二个问题:过半机制
- redis
# 渐进式 rehash
# 定义
扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht[1] 里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。
这样做的原因在于, 如果 ht[0] 里只保存着四个键值对, 那么服务器可以在瞬间就将这些键值对全部 rehash 到 ht[1] ; 但是, 如果哈希表里保存的键值对数量不是四个, 而是四百万、四千万甚至四亿个键值对, 那么要一次性将这些键值对全部 rehash 到 ht[1] 的话, 庞大的计算量可能会导致服务器在一段时间内停止服务。
因此, 为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0] 里面的所有键值对全部 rehash 到 ht[1] , 而是分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash 到 ht[1]
# 过程
以下是哈希表渐进式 rehash 的详细步骤:
- 为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表
- 在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始
- 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一
- 随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量
# 具体过程






- 因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类
- 另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表
# 大key问题
# 何为大key
- 单个简单的key存储的value很大
- hash, set,zset,list 结构中存储过多的元素
- 一个集群存储了上亿的key(存储的key越多,约占用内存)(未看)
- 大Bitmap或布隆过滤器(未看)
# 大key场景
Redis使用者应该都遇到过大key相关的场景,比如:
- 热门话题下评论、答案排序场景
- 大V的粉丝列表
- 使用不恰当,或者对业务预估不准确、不及时进行处理垃圾数据等
# 引发的问题
- 集群模式在slot分片均匀情况下,会出现数据和查询倾斜情况,部分有大key的Redis节点占用内存多,QPS高
- 主动删除、被动过期删除、数据迁移等,由于处理这一个KEY时间长,导致服务端发生阻塞
- 如果为list,hash等数据结构,大量的elements需要多次遍历,多次系统调用拷贝数据消耗时间
# 发现大key
- redis-cli --bigkeys命令:可以找到某个实例5种数据类型(String、hash、list、set、zset)的最大key

- redis-rdb-tools工具:redis实例上执行bgsave,然后对dump出来的rdb文件进行分析,找到其中的大KEY

- 单个key查看: debug object key: 查看某个key序列化后的长度,每次看1个key的信息,比较没效率
- Redis 4.0引入了memory usage命令和lazyfree机制(Lazyfree的原理是在删除的时候只进行逻辑删除,把key释放操作放在bio(Background I/O)单独的子线程处理中,减少删除大key对redis主线程的阻塞,有效地避免因删除大key带来的性能问题。在此提一下bio线程,很多人把Redis通常理解为单线程内存数据库, 其实不然。Redis将最主要的网络收发和执行命令等操作都放在了主工作线程,然而除此之外还有几个bio后台线程)
# 如何删除大key
- 分批删除
- lazyfree机制:unlink命令:代替DEL命令;会把对应的大key放到BIO_LAZY_FREE后台线程任务队列,然后在后台异步删除
# 大key的拆分方案
- 单个简单的key存储的value很大
- 该对象需要每次都整存整取 :可以尝试将对象分拆成几个key-value,这样分拆的意义在于分拆单次操作的压力,将操作压力平摊到多个redis实例中,降低对单个redis的IO影响;
- 该对象每次只需要存取部分数据:可以像第一种做法一样,分拆成几个key-value, 也可以将这个存储在一个hash中,每个field代表一个具体的属性,使用hget、hmget来获取部分的value,使用hset,hmset来更新部分属性
- value中存储过多的元素:对于value中存储过多元素的key,同样可以将这部分元素拆分,以hash为例,正常的流程是:hget(hashKey, field);hset(hashKey, field, value)。 现在可以固定一个桶数量,比如1w,每次存取的时候,先在本地计算field的hash值,对1w取模,确定field落在哪个key上,newHashKey = hashKey + ( hash(field) % 10000); hset (newHashKey, field, value) ; hget(newHashKey, field),set,zset,list做法类似 (但有些不适合的场景,比如List,要保证 lpop 的数据的确是最早push到list中去的,可以按照时间来分拆)
- 一个集群存储了上亿的key(存储的key越多,约占用内存)(未看)
- 大Bitmap或布隆过滤器(Bloom )拆分(未看)
# 热key问题
# 定义
瞬间有几十万的请求去访问redis上某个固定的key,从而压垮缓存服务的情况;比如XX明星结婚。那么关于XX明星的Key就会瞬间增大,就会出现热数据问题;那接下来这个key的请求,就会直接怼到你的数据库上,导致你的服务不可用
# 发现热key
- 凭借业务经验,进行预估哪些是热key:其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key
- 在客户端进行收集:这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵
- 在Proxy层做收集:有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy;(Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis或memcached服务器)
- redis 命令 -hotkeys:redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上--hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢
- redis命令 monitor:该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能
- 自己抓包评估:Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性
# 业内解决方案
# 二级缓存
比如利用ehcache,或者一个HashMap都可以。在你发现热key以后,把热key加载到系统的JVM中。针对这种热key请求,会直接从jvm中取,而不会走到redis层。假设此时有十万个针对同一个key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。现在假设,你的应用层有50台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有2000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形
# 备份热key
这个方案也很简单。不要让key走到同一台redis上不就行了。我们把这个key,在多个redis上都存一份不就好了。接下来,有热key请求进来的时候,我们就在有备份的redis上随机选取一台,进行访问取值,返回数据,伪代码:
const M = N * 2
//生成随机数
random = GenRandom(0, M)
//构造备份新key
bakHotKey = hotKey + “_” + random
data = redis.GET(bakHotKey)
if data == NULL {
data = GetFromDB()
redis.SET(bakHotKey, expireTime + GenRandom(0,5))
}
# 缓存预热
# 定义
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统 这样可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据
# 方案
# 缓存刷新页面
直接写个缓存刷新页面,上线时手工操作
# 项目启动自动加载
数据量不大,可以在项目启动的时候自动进行加载
# 布隆过滤器
# 原理

- 新增key:布隆过滤器底层是用bitmap,有多个hash函数;例如key = 你好,通过hash函数求余计算出下标,并将下标位置改为1;可以通过计算一个key所对应的下标是否是1,如果都是1(有误判可能,但是误判率很低0.0几),则表示key存在;否则,key不存在;
- 删除key:一般布隆过滤器不删除key,因为下标的位置1可能是用来表达其他key的,如果还原成0,其他key可能也被删除了
如果布隆过滤器中有,则表示不一定有 如果布隆过滤器中没有,则表示一定没有
# 解决缓存穿透

问题:要把所有的key都放到布隆过滤中;有一定误判,其实这个误判不怎么影响 (看这个图要先明确一点:要先把数据库里的数据都放到步隆过滤器中;步隆说有,不一定真的有,还要去缓存和数据库中找;红叉号表示就布隆中有,但是数据库中没有,也不要把布隆中的删掉)
# 缓存穿透/缓存击穿/缓存雪崩
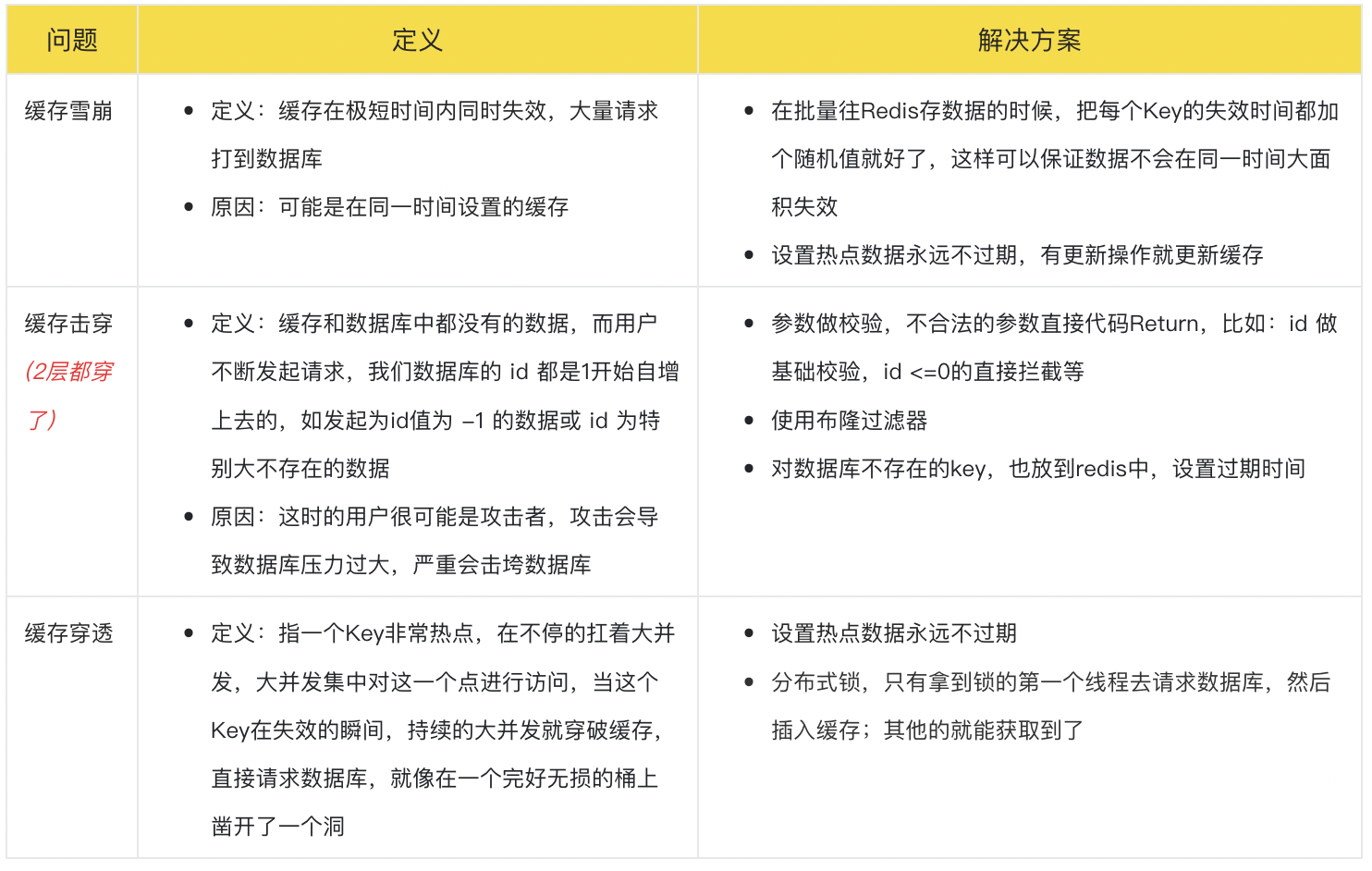 (注意:上图缓存穿透和击穿写反了)
(注意:上图缓存穿透和击穿写反了)
# 过期数据处理策略于内存淘汰策略
# 过期处理策略

Redis中同时使用了惰性过期和定期过期两种过期策略
# 内存淘汰策略
指在增加新key但是redis内存不足的情况:
| noeviction(默认策略) | 新写入操作会报错 |
|---|---|
| allkeys-lru | 在键空间中,移除最近最少使用的key |
| allkeys-random | 在键空间中,随机移除某个key |
| volatile-lru | 仅对设置了过期时间的键采取LRU淘汰 |
| volatile-random | 仅对设置了过期时间的键,随机移除某个key |
| volatile-ttl | 仅对设置了过期时间的键,有更早过期时间的key优先移除 |
# redis事务
# 原理
MULTI、EXEC [ɪɡˈzek]、DISCARD、WATCH是事务的基础。用来显式开启并控制一个事务,它们允许在一个步骤中执行一组命令。并提供两个重要的保证:
- 事务中的所有命令都会被序列化并按顺序执行。在执行Redis事务的过程中,不会出现由另一个客户端发出的请求。这保证命令队列作为一个单独的原子操作被执行。
- 队列中的命令要么全部被处理,要么全部被忽略。EXEC命令触发事务中所有命令的执行,因此,当客户端在事务上下文中失去与服务器的连接:
- 如果发生在调用MULTI命令之前,则不执行任何commands
- 如果在此之前EXEC命令被调用,则所有的commands都被执行
Redis事务不支持Rollback:在事务执行时有些命令可能会失败,但仍会继续执行剩余命令而不是Rollback(事务回滚)
入队错误: 在命令入队的过程中,如果客户端向服务器发送了错误的命令,比如命令的参数数量不对,所有命令都不会执行
执行错误: 如果命令在事务执行的过程中发生错误,比如说,对一个不同类型的 key 执行了错误的操作,那么 Redis 只会将错误包含在事务的结果中,这不会引起事务中断或整个失败,不会影响已执行事务命令的结果,也不会影响后面要执行的事务命令
# 相关命令
| 命令 | 作用 | 说明 |
|---|---|---|
| WATCH | 将给出的Keys标记为监测态,作为事务执行的条件 | 乐观锁 |
| UNWATCH | 清除事务中Keys的 监测态,如果调用了EXEC or DISCARD,则没有必要再手动调用UNWATCH | |
| MULTI | 显式开启redis事务,后续commands将排队,等候使用EXEC进行原子执行 | multi 命令不能嵌套 |
| EXEC | 执行事务中的commands队列,恢复连接状态。如果WATCH在之前被调用,只有监测中的Keys没有被修改,命令才会被执行,否则停止执行(CAS机制) | |
| DISCARD | 清除事务中的commands队列,恢复连接状态。如果WATCH在之前被调用,释放监测中的Keys |
# 用法
// 开启事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379> multi
(error) ERR MULTI calls can not be nested
// 命令入列
> multi
OK
> set k v
QUEUED
> get k
QUEUED
// 执行事务
> multi
OK
> set k v2
QUEUED
> exec
1) OK
> get k
"v2"
// 放弃事务,discard:清空队列
> multi
OK
> set k v3
QUEUED
> discard
OK
> get k
"v2"