
# 为什么需要分库分表

# 单用户表超过 500 万解决方案
按照用户来拆分订单表,但是单个用户的订单量可能就超过500W,可以将订单数据划分成两大类型:分别是热数据和冷数据
- 热数据:3 个月内的订单数据,查询实时性较高;使用 mysql 进行存储
- 冷数据 A:3 个月 ~ 12 个月前的订单数据,查询频率不高;对于这类数据可以存储在ES中,了利用搜索引擎特性基本上可以做到较快的查询
- 冷数据 B:1 年前的订单数据,几乎不会查询,只有偶尔的查询需求;对于这类不经常查询的数据,可以存放到Hive中
# 分片方案
- Hash取模方案(主流方案):在我们设计系统之前,可以先预估一下大概这几年的订单量,如:4000 万。每张表我们可以容纳 500 万,也我们可以设计 8 张表进行存储
- 优点:订单数据可以均匀的放到那 4 张表中,这样此订单进行操作时,就不会有热点问题
- 缺点:将来的数据迁移和扩容,会很难。数据不连续
- Range范围方案
- 优点:有利于扩容,不需要数据迁移
- 缺点:有热点问题(有些节点可能会被频繁查询压力较大,热数据节点就成为了整个集群的瓶颈。而有些节点可能存的是历史数据,很少需要被查询到)
- 分组思想:先按范围进行分组。比如 0-4000 万分到 group1,然后 group1 中再进行 Hash 分,这样当扩容的时候,直接新增一个 group2,存储 4000 万到 8000 万的数据。然后每个组里的表或者库再进行 Hash 分(也会有热点问题,只不过之前热点问题是在一张表上,现在变成了一个group,一般不用这种)
- 一致性hash
# 具体方案
# 水平分库

概念:以字段 (partition key) 为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中
结果:
- 每个库的结构都一样
- 每个库的数据都不一样,没有交集
- 所有库的并集是全量数据
# 水平分表

同水平分库
# 垂直分库

概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中 结果:
- 每个库的结构都不一样
- 每个库的数据也不一样,没有交集
- 所有库的并集是全量数据
分析:到这一步,基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化(例如交易库和交易日志库可以算作垂直分库)
# 垂直分表

# 分库分表工具
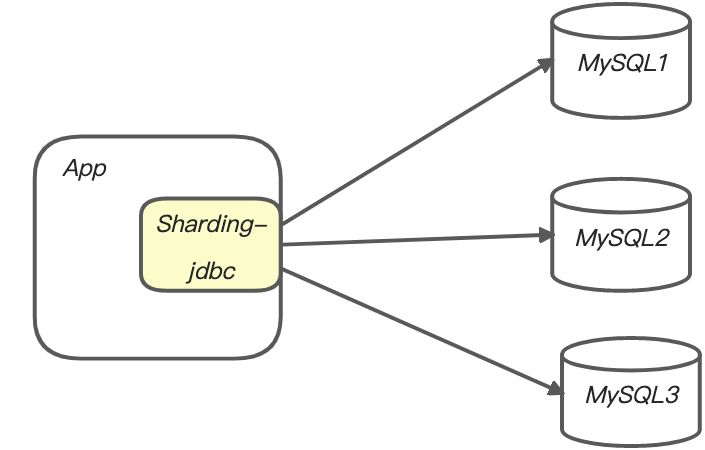
Sharding-jdbc
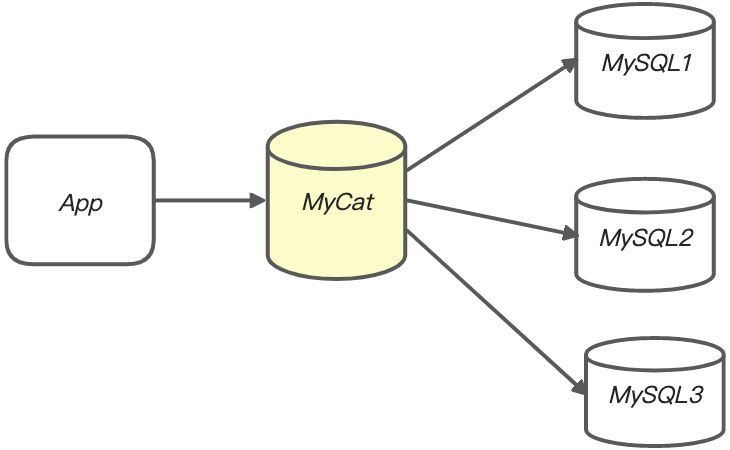
mycat
对比:
- mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
- 使用mycat时不需要改代码,而使用sharding-jdbc时需要修改代码
# 分库分表问题
# 水平分表:非partition key的查询问题
(查询订单号为413742291618304的订单,不指定公司)
解决方案1:映射法(这真不是个好方法,虽然映射表只有2个字段)

解决方案2:基因法(不错)

如果 partition key 是uid,tid字段不是partition key,可以把分库基因组装到tid的末尾;当使用tid去查询时,可以通过基因先确定分库号
# 水平分库分表:非partition key跨库跨表分页查询问题
- 用 NoSQL法 解决(ES等)
- order by ... limit 100:从多个库中查查出来,然后在内存里再排一次序,再分一次页
# 扩容问题
为什么通常是扩容2倍?
A:如果是分库分表结构; 分库号 = companyId%库数,这样会有一半分companyId保存在原来的库 分表号 = companyId%表数,这样会有一半分companyId保存在原来的表 可以少迁移部分数据
扩容方案:
- 停机迁移
- 双写迁移方案(通用做法)
- 配置双写

- 新库同步老库数据

- 后台临时工具迁移完数据后,要再次检查单库单表中的数据是否和分库分表中的数据一模一样,如果一样,则迁移结束;否则,判断是否覆盖分库分表中的数据;依次循环往复,直到一模一样
- 修改配置,去掉单库单表的数据源,读写都在分库分表上
- 升级从库法:从库同步主库的所有数据,然后从库升级为主库,然后把从库中不属于自己的数据删除